#30 si me acabo de meter en kaggle, la verdad que igual es jodido aprender con tan pocos datos para el resto de colores
Gray
83%
Cinnamon
13%
Other (81)
3%


#28 no tiene porque. depende del tama;o de la muestra. cuanto mas datos tienes mas cierta es esa afirmacion. pero hasta que no validas en el mundo real nunca lo sabras. si tu sampleas en random, cuanto menos datos tengas, menos fiable es tu analisis.
para estos ejemplos puedes suponerlo. la manera de comprobarlo es facil. miras el tama;o de test y de train. vuelve a juntarlo y vuelve a sacar el mismo % con randoms. mira la distribucion. se mantiene estable?
#31 como te he dicho, intenta sacar el 13 y el 3 con 100% accuracy XD
el desbalanceo es bastante normal.

#23 Todavia no, pero si he hecho varios experimentos y me empiezo a plantear que la mayoria de las variables son ruido, solo he encontrado algo de señal en los datos geospaciales.

#32 claro, pero eso es teoría estadística de muestreo. Para intentar que los datos sean representativos se hacen muestreos estratificados.
#32 sobre todo teniendo en cuenta que la muestra de esos colores es muy poca, al final es mas un problema de detección de outliers de grises mas que clasificar realmente. La verdad que apenas he mirado el challenge solo comente que me sorprendió el desbalanceo y que no me gusta que el test este así.
#35 pues yo lo veo un problema genial para novatos. hay mil cosas para aprender y ademas es un ejemplo realista.
analisis de datos, feature reduction, cunfusion matrix, oversampling, distintos algoritmos y ensamblajes que puedes usar, automatizar las pipelines de entrenamiento para que te haga todo lo anterior automaticamente...
quizas falla en el problema que la evaluacion no es ponderada. pero a ver, esto es sentido comun. si clasificas es porque las 3 categorias son igual de importantes.
#36 pues yo lo veo al reves para novatos creo que lo ideal seria tener un test balanceado y que cuando tengan ellos en su validación un 80% de acc vayan al challenge y saquen un 33% se hagan preguntar y empiecen a plantearse qué pasa y qué deben hacer, que igual alguien como ha pasado en este hilo, va y saca un 83% y dice bueno flipa un 80% de acc.....ya que tener un test desbalanceado hace que la medida de acc que va de 0-100 pierde su representatividad visual rápida. Pero vamos que es mi humilde opinión.

Si, admito que tras hacer yo mismo unos tests la cosa está más accidentada de lo que esperaba, pero siempre hay alguna manera de sacarlo adelante. Para la siguiente hare tests antes de empezar la competición, pero también me da cosa ponerlo demasiado fácil y que unos cuantos saquen 100% perdiendo toda la gracia
#39 nada tranquilo si es un debate mas de gustos y ¿comodidad?, no creo que si estuviera balanceado el test el challenge fuera mas fácil o difícil, simplemente sería menos toca huevos medir como de bien o mal lo haces realmente.
#41 puedes usar F1, es una métrica equilibrada entre los errores tipo I y tipo II.
Dejo esto por si es de ayuda:
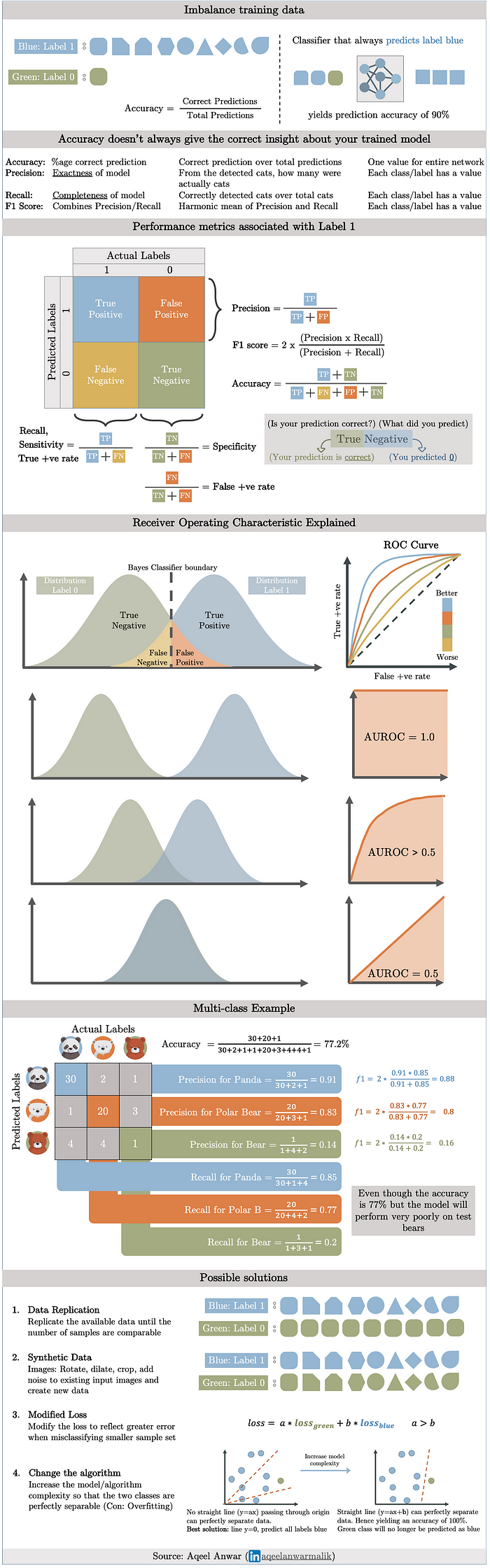 https://towardsdatascience.com/a-walk-through-imbalanced-classes-in-machine-learning-through-a-visual-cheat-sheet-974740b19094
https://towardsdatascience.com/a-walk-through-imbalanced-classes-in-machine-learning-through-a-visual-cheat-sheet-974740b19094
#42 ya bueno si por hacer se pueden hacer muchas cosas, pero si no tienes el ground truth del test pues poca cosa, dependes de lo que te devuelva kaggle tras subir el test, en este caso el acc.
#43 tienes razón, no te había entendido porque no tengo ni idea de Kaggle. Supongo que siendo una competición interna, entre nosotros para aprender, no tiene importancia pero lo suyo sería no tomar accuracy como métrica de referencia.
Siempre podeis extraer otro subset de validation y hacer vuestras cábalas con ese set, y para el modelo final incluirlo en los datos a procesar
He raspado algun outlier para llegar a 84%, la verdad que esta dificl este dataset, a ver si os animais alguno mas!
Despues de varios experimentos todos fallidos hasta aqui he llegado, me temo que la mayoria de las variables no aportan mas que ruido a la hora de predecir el color de la ardilla.
Si alguien encuentra algo interesante me reenganchare.

#50 Has probado a trabajarte un poco las variables de coordenadas? A mí se me ocurrió hacer un grid en los extremos de las coordenadas y jugar un poco con la resolución a ver si emerge alguna agrupación espacial. Pero no he tenido mucho tiempo.
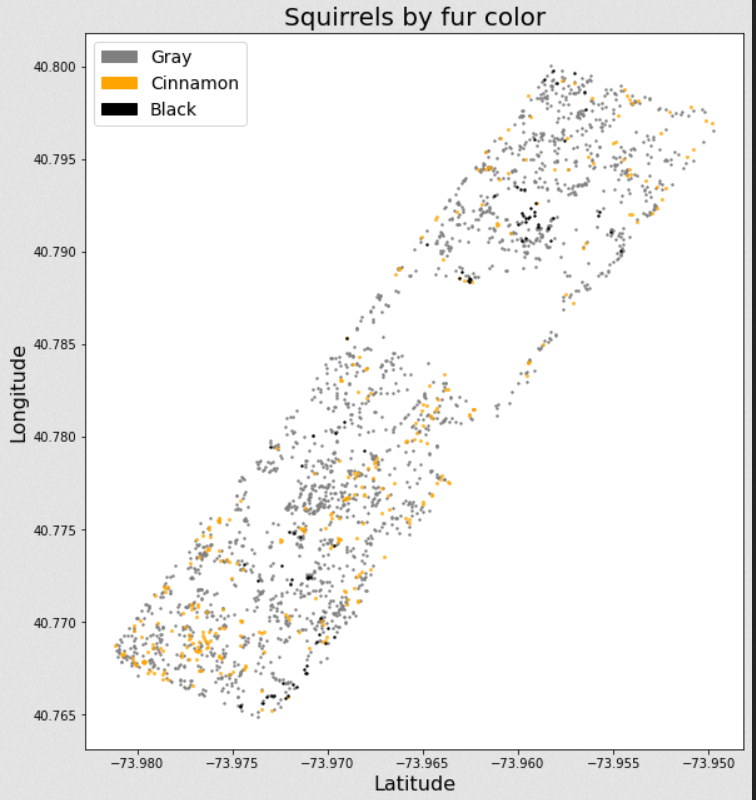
A mi es que me pilla una semana muy muy mala de mucho curro no se si sacare tiempo pero me apetece darle un try si es dificil la verdad por curiosidad.
#50 voy a intentar ayudarte o darte ideas tipicas del proceso.
que feature engineering has hecho?
has analizado que variables aportan la misma (o nula) informacion? si aportan lo mismo las puedes combinar o descartar.
has tirado de PCA o similar y ver si es mas facil clasificar? con menos dimensiones y segun su tipo puedes probar distintos algos.
i.e no se que has probado.
tampoco se me ocurre mucho mas. yo siempre hacia lo que puse en #36. y de ahi solia sacar algun modelo que iba bien.
#55 He probado bastantes o al menos lo mas basico, PCA todavia no pero no le tengo muchas esperanzas
Asi por encima experimentos que he hecho, lo pongo en spoiler por si alguien no quiere influenciarse por lo que ya han hecho otros


#56 Jodido, se me ocurren pocas cosas mas.
Cuando haces el oversampling del 3% y luego analizas, si mantienes los scores, en teoria es que lo estas haciendo bien, por tanto ahi podrias sacarn un clasificador mejor. porque ya tendrias una distribucion 33% 33% 33%.
#59 Enhorabuena! Me hubiera gustado poder dedicarle más tiempo para probar otras cosas, me estaba picando no conseguir casi pasar del baseline.
Ahora qué? Se exponen las soluciones? Que no sé cómo va esto. xD

